Здравствуйте, уважаемые читатели. Давайте разберемся как убрать дубли страниц вашего сайта, что такое дубли контента и почему они появляются.
Что такое дубли страниц?
На вашем сайте могут появиться дубликаты страниц, которые своим содержанием полностью соответствуют другим страницам. Например вы готовили статью и случайно опубликовали несколько ее копий, или что-то тестировали на странице и забыли удалить, также дубли могут создавать страницы подготовки вывода содержимого на печать Эти дубликаты, не содержат никакой смысловой нагрузки и являются своего рода «паразитами».
Чем вредны дубли страниц?
Во-первых поисковый робот при обходе вашего сайта видит одинаковый контент на разных страницах и соответственно понижает рейтинг.
Во- вторых наличие дополнительных страниц создает дополнительную нагрузку на хостинг и увеличивает время загрузки страниц.
Соответственно надо избавляться от дублей страниц (запрещать индексацию поисковикам). Существует несколько способов как справиться с этой проблемой:
- Установить специальные плагины;
- Внести изменения в код шаблона сайта, запрещающий индексирование страниц;
- Запретить индексацию определенных страниц, отредактировав файл robots.txt
Я как новичок в сайтостроении, пока не совсем разобрался как избавляться от дублирования контента внесением правки в код шаблона сайта. Плагинов полностью отвечающим за удаление дублированного контента, я тоже пока не нашел.Поэтому предлагаю решить проблему при помощи внесения правок в файл robots.txt, который установлен в корневой директории вашего сайта.
Ищем дубли страниц.
Для этого выбираете уже проиндексированную статью. Копируете два три предложения текста вашей статьи и вставляете скопированный отрывок в строку поиска браузера.
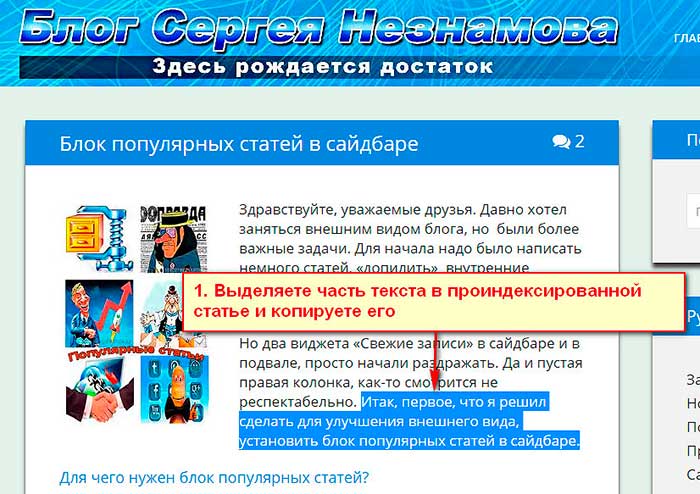

Причем скопированный текст, для уточнения поиска, надо ввести с кавычками. Нажимаем «Найти»
Если в результатах поисковой выдачи вы видите больше одной страницы, значит все остальные являются дублями.
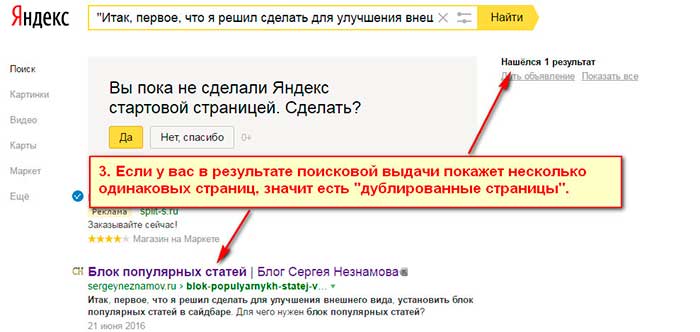
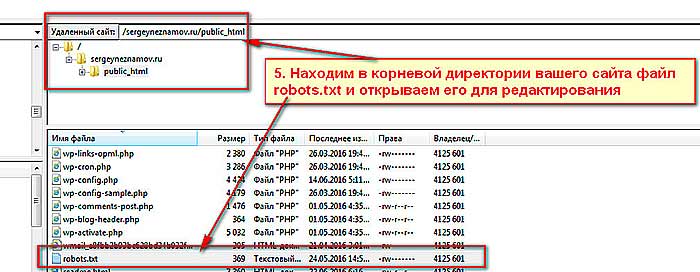
Проверяете аналогично все страницы сайта и выписываете себе в блокнот названия дублирующих страниц. Далее при помощи файлового менеджера вашего хостинга или с помощью FTP-клиента заходите в корневую директорию сайта для редактирования файла robots.txt.
Убираем дубли страниц.
В robots.txt прописываете для поискового робота запрещающую индексирование директиву Disallow. Перечисляете все ранее выписанные в блокнот, названия дублирующих страниц. Внешне строка выглядит примерно так Disallow: /site-page2.
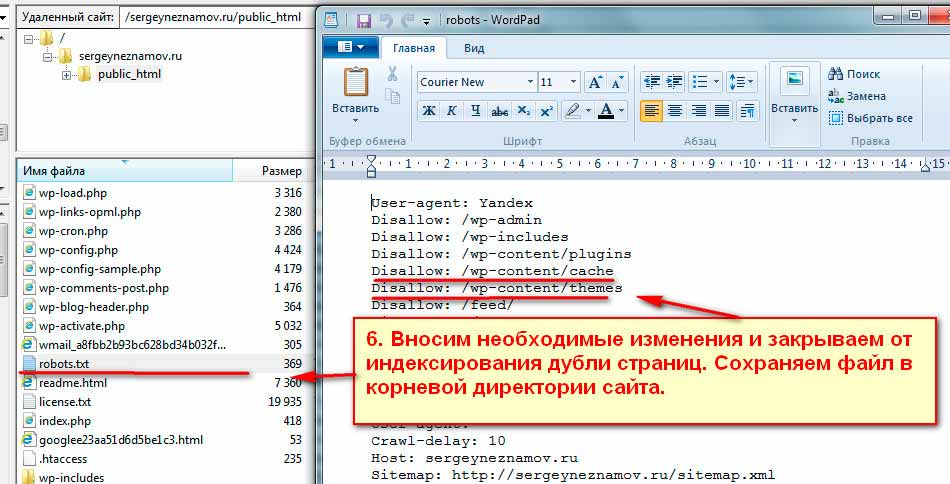
После внесения изменеий , сохраняете обновленный файл в корневой директории сайта. После очередного посещения поисковым роботом вашего ресурса, он сам удалит дублирующие страницы.
Вот и все, как видите совсем не сложно. Друзья, если вам статья оказалась полезной, пожалуйста оставьте свои комментарии. С уважением.





Тамара, не стоит благодарности. Статьи из карты сайта можно закрыть от индексации в robots.txt. Удачи!
Сергей огромное вам спасибо, благодаря вашей статье нашла более 30 дублированных статьей! Наверное из-за этого просели позиции моего сайта! Я добавляю новые статьи, постоянно их продвигаю через соцсети, а сайт опускается в поисковой выдаче! Подскажите у меня в поиске показывает даже статьи из карты сайта, это тоже дубли и их надо удалять? Спасибо вам за подсказки!
Если вы в robots.txt пропишите запрет на индексацию определенных страниц, то при очередном посещении роботом вашего сайта он не будет их индексировать в том числе и написанные ранее. Конечно можно воспользоваться и плагином или закрыть индексацию дублей при помощи кода. Я в статье описал один из вариантов. Удачи!
Хорошая статья, однако способ изменения robots.txt подойдет для новых блогов, а если на нем уже есть 200-300 статей, думаю лучше воспользоваться плагином.